Extra: Two-stage energy dispatch optimization with wind curtailment#
This notebook illustrates a two-stage stochastic optimization problem in the context of energy systems where there are recourse actions that depends on the realization of the uncertain parameters.
# install dependencies and select solver
%pip install -q amplpy matplotlib networkx numpy pandas
SOLVER = "highs"
from amplpy import AMPL, ampl_notebook
ampl = ampl_notebook(
modules=["highs"], # modules to install
license_uuid="default", # license to use
) # instantiate AMPL object and register magics
Preliminaries#
The equilibrium point for the European power network, which operates on alternating current, is at a frequency of 50 Hertz with a tolerance threshold of +- 0.05 Hertz. Power network operators are responsible for maintaining a constant frequency on the network. The way that operators do this is mainly by perfectly balancing power supply and demand.
But what happens if power supply does not meet demand? When supply exceeds demand, then the electrical frequency increases. If demand exceeds supply, then the frequency drops. Since power plants are designed to operate within a certain frequency range, there is a risk that they will disconnect from the grid after a period of time. If the frequency deviates too much from the 50 Hertz, then there is a risk that the power plants switch off one after another,potentially leading to a complete power blackout.
Using conventional power generators such as coal and gas, power supply and demand are often matched by increasing/decreasing the production rate of their power plants and taking generating units on or off line. With the advent of renewable energy sources, it has become increasingly more difficult to match supply and demand. Besides not being controllable power sources, network operators rely on forecasting models to predict the power generated by renewable sources. In practice, this prediction is fairly accurate for solar energy, but wind energy is particularly difficult to predict correctly.
The goal of this notebook is to ensure that power demand meets supply while taking into account wind fluctuations. We will introduce two optimization problems and solve them as stochastic optimization problems. Read first the energy dispatch problem from the Chapter 4 for the preliminaries on power networks and the Optimal Power Flow (OPF) problem. An important difference from the setting there, is that here we will not assume that the wind generation is a decision variable. Instead, wind generation is a random variable, as will be explained later on. We do assume that solar and hydro power are decision variables, since the former is accurately predicated whereas the latter is controllable.
Unit Commitment#
We now consider another optimization problem relevant for energy systems named the Unit Commitment (UC) problem. UC is an extended version of the OPF problem in which an additional binary decision variable \(x_i\) is introduced to decide whether generator \(i\) should be activated or not. In this formulation we include a fixed cost \(\kappa_i\) that is incurred for the activation of a generator \(i\), which is also added as a new parameter c_fixed to the network instance.
In practice, the UC problem is often considered as a two-stage problem. Since it takes time to activate gas and coal generators before they can produce energy, this decision must be made in advance, i.e., as here-and-now decision in the first stage. In the second stage, we then decide the power generation levels of the (activated) coal and gas generators. Note that, in particular, we cannot produce from generators we did not already turn on! Lastly, the UC still includes the same physical constraints as the OPF, i.e., power generation limits and line capacity constraints.
All solar and hydro generators are activated by default. Solar power is treated as deterministic in the sense that in the instance that you are given it holds that \(p_{\min}=p_{\max}\) for solar generators. Hydro generators are still controllable within their nontrivial generation limits.
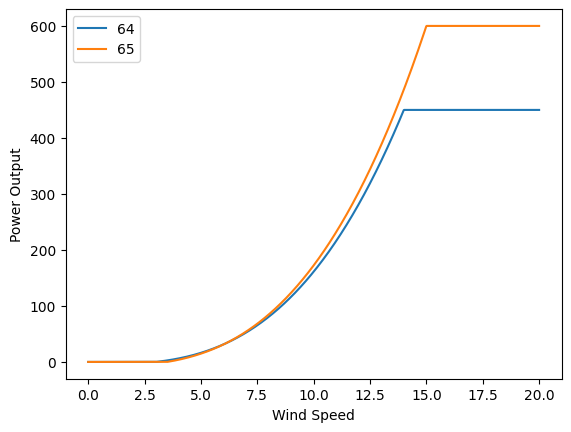
The uncertainty will be described in terms of the wind speed \(v\) instead of the wind power. To determine the wind power resulting from a given wind speed, you need to use a so-called power curve \(g_i(\cdot)\) for a wind generator \(i\), which is an explicit function that maps the wind speed \(v\) to a wind power \(g_i(v)\). In the network instance that you are given, there are two wind generators, one in node 64 which is an on-shore wind park, and one in node 65 which is a off-shore wind park. Being structurally different, they have different power curves. See below a plot of the power curve function for the on-shore wind generator.

An analytical description of the power curves is given as follows
We now present the two-stage UC problem formulation. In the first stage, we decide which coal and gas generators to activate (all wind, solar and hydro generators are active by default). In the second stage, the exact power output of the wind parks is calculated using the power curves knowing the realization of the two wind speeds and the power outputs of the already activated generators needs to be adjusted to match demand exactly.
where
Package and data import#
# Load packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
import time
# Download the data
base_url = "https://raw.githubusercontent.com/ampl/mo-book.ampl.com/dev/notebooks/10/"
nodes_df = pd.read_csv(base_url + "nodes.csv").set_index("node_id")
edges_df = pd.read_csv(base_url + "edges.csv").set_index(["node_id1", "node_id2"])
# Replace 'na' by an empty string
nodes_df.fillna("", inplace=True)
network = {"nodes": nodes_df, "edges": edges_df}
Network data#
This notebook uses the same network as in energy dispatch problem and hence the same data structure. In particular, the nodes and edges of the network are stored in the nodes and edges dataframes, respectively. The edges dataframe contains the following columns:
node_id1: first node of a given edge;node_id2: second node of a given edge;f_max: describing the maximum power flow capacity of the edge; andb: the susceptance of the edge.
edges_df
| b | f_max | ||
|---|---|---|---|
| node_id1 | node_id2 | ||
| 0 | 1 | 10.0100 | 270.705509 |
| 2 | 23.5849 | 415.734756 | |
| 3 | 4 | 125.3133 | 265.273978 |
| 2 | 4 | 9.2593 | 400.159230 |
| 4 | 5 | 18.5185 | 217.852748 |
| ... | ... | ... | ... |
| 64 | 65 | 28.9059 | 1200.000000 |
| 67 | 68 | 28.9059 | 1200.000000 |
| 80 | 79 | 28.9059 | 1200.000000 |
| 86 | 85 | 4.8216 | 602.814908 |
| 67 | 115 | 246.9136 | 1200.000000 |
179 rows × 2 columns
The network includes 18 generators of different type, which is described in the energy_type field. We distinguish between conventional generators (coal, gas) and renewable generators (hydro, solar, wind). Every conventional generator node has two parameters:
c_fixed, describing the activation cost of the conventional generators;c_var, describing the unit cost of producing energy for each conventional generator
Renewable generators are assumed to have zero marginal cost and zero activation cost. Nodes 64 and 65 correspond to the two wind generators that this notebook focuses on.
nodes_df
| d | p_min | p_max | c_var | is_generator | energy_type | c_fixed | |
|---|---|---|---|---|---|---|---|
| node_id | |||||||
| 0 | 44.230344 | 0.0 | 0.0 | 0 | False | 0 | |
| 1 | 17.690399 | 0.0 | 0.0 | 0 | False | 0 | |
| 2 | 35.514209 | 0.0 | 0.0 | 0 | False | 0 | |
| 3 | 35.248977 | 0.0 | 0.0 | 0 | False | 0 | |
| 4 | 0.000000 | 0.0 | 0.0 | 0 | False | 0 | |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 113 | 6.784856 | 0.0 | 0.0 | 0 | False | 0 | |
| 114 | 19.664045 | 0.0 | 0.0 | 0 | False | 0 | |
| 115 | 163.009206 | 0.0 | 0.0 | 0 | False | 0 | |
| 116 | 16.175633 | 0.0 | 0.0 | 0 | False | 0 | |
| 117 | 31.504459 | 0.0 | 0.0 | 0 | False | 0 |
118 rows × 7 columns
nodes_df[nodes_df.is_generator]
| d | p_min | p_max | c_var | is_generator | energy_type | c_fixed | |
|---|---|---|---|---|---|---|---|
| node_id | |||||||
| 9 | 0.0 | 0.000000 | 400.000000 | 0 | True | hydro | 0 |
| 11 | 0.0 | 0.000000 | 200.000000 | 0 | True | hydro | 0 |
| 24 | 0.0 | 0.000000 | 422.086431 | 28 | True | coal | 1689 |
| 25 | 0.0 | 0.000000 | 227.384370 | 18 | True | coal | 1057 |
| 30 | 0.0 | 0.000000 | 235.306239 | 19 | True | coal | 1837 |
| 45 | 0.0 | 0.000000 | 371.349675 | 19 | True | coal | 1456 |
| 48 | 0.0 | 227.262510 | 227.262510 | 0 | True | solar | 0 |
| 53 | 0.0 | 97.526012 | 97.526012 | 0 | True | solar | 0 |
| 58 | 0.0 | 284.753966 | 284.753966 | 0 | True | solar | 0 |
| 60 | 0.0 | 98.693808 | 98.693808 | 0 | True | solar | 0 |
| 64 | 0.0 | 16.050352 | 16.050352 | 0 | True | wind | 0 |
| 65 | 0.0 | 77.747257 | 77.747257 | 0 | True | wind | 0 |
| 79 | 0.0 | 0.000000 | 360.554867 | 38 | True | gas | 1504 |
| 86 | 0.0 | 0.000000 | 445.397099 | 38 | True | gas | 1751 |
| 88 | 0.0 | 0.000000 | 298.390683 | 33 | True | gas | 2450 |
| 99 | 0.0 | 0.000000 | 440.534057 | 33 | True | gas | 2184 |
| 102 | 0.0 | 0.000000 | 454.660581 | 35 | True | gas | 1617 |
| 110 | 0.0 | 0.000000 | 451.133883 | 34 | True | gas | 1627 |
Wind turbines risk to break if the wind speed is too high, so wind turbines need to be curtailed (i.e., deactivated) once the wind speed exceeds a specified maximum speed \(v_{\max}\). An additional second stage decision is therefore needed to decide whether to curtail the wind turbines or not. We include this additional requirement in the second-stage formulation, assuming that we have \(T\) samples available.
Assume that
\(v_{64} \sim \text{Weibull}\) with scale parameter 15 and shape parameter 2.6.
\(v_{65} \sim \text{Weibull}\) with scale parameter 18 and shape parameter 3.0.
We sample \(T=100\) data points from these two distributions. Using these data points, compute the average wind speeds. Then compute the objective value. Analyze the differences in the objective value and explain the differences.
def g_offshore(v):
return np.piecewise(
v, [v <= 3.5, v > 15], [0, 600, lambda v: 0.18007 * v**3 - 7.72049]
)
def g_onshore(v):
return np.piecewise(
v, [v <= 3, v > 14], [0, 450, lambda v: 0.16563 * v**3 - 4.4718]
)
# assign wind generators
g_func = {64: g_onshore, 65: g_offshore}
# show plots
v = np.linspace(0, 20, 1000)
for i in g_func.keys():
plt.plot(v, g_func[i](v), label=i)
plt.legend()
plt.xlabel("Wind Speed")
plt.ylabel("Power Output")
Text(0, 0.5, 'Power Output')
%%writefile uc_windcurtailment.mod
set T;
set V;
set E within {V, V};
set W;
set NW;
param d{V};
param p_min{V};
param p_max{V};
param c_var{V};
param is_generator{V};
param energy_type{V} symbolic;
param c_fixed{V};
param b{E};
param f_max{E};
param vmax{W};
param samples{W, T};
param g{W, T};
param M;
# Declare decision variables
# Binary variable indicating whether a generator is on or off
var x{V} binary;
# Power generation of each generator
var p{V, T} >= 0;
# Voltage angle of each node
var theta{V, T};
# Power flow on each edge
var f{(i,j) in E, T} <= f_max[i,j], >= -f_max[i,j];
# Binary variable indicating whether a wind turbine is curtailed (0) or not (1)
var y{W, T} binary;
# Objective function, with the goal of minimizing the total cost of generation
var term1 =
sum{i in V: energy_type[i] in {"coal", "gas"}} M * x[i];
var term2{t in T} =
sum{i in V: is_generator[i] == 1} c_var[i] * p[i, t];
minimize objective:
term1 + sum{t in T} term2[t] / card(T);
# Declare constraints
# Wind power output is equal to the wind speed times the wind turbine capacity, if the wind turbine is not curtailed
s.t. wind_speed_to_power{i in W, t in T}:
p[i, t] == (1 - y[i, t]) * g[i, t];
s.t. wind_curtailment{i in W, t in T}:
samples[i, t] <= vmax[i] + y[i, t] * M;
s.t. generation_upper_bound{i in NW, t in T}:
p[i, t] <= x[i] * p_max[i];
s.t. generation_lower_bound{i in NW, t in T}:
p[i, t] >= x[i] * p_min[i];
# Net flow in every node must be equal to the power generation minus the demand in that node
var incoming_flow{i in V, t in T} = sum{j in V: (j, i) in E} f[j, i, t];
var outgoing_flow{i in V, t in T} = sum{j in V: (i, j) in E} f[i, j, t];
s.t. flow_conservation{i in V, t in T}:
incoming_flow[i, t] - outgoing_flow[i, t] == p[i, t] - d[i];
s.t. susceptance{(i,j) in E, t in T}:
f[i, j, t] == b[i, j] * (theta[i, t] - theta[j, t]);
Overwriting uc_windcurtailment.mod
def UC_windcurtailment(network, samples, g, vmax):
df_nodes = network["nodes"]
df_edges = network["edges"]
# Define a model
model = AMPL()
model.read("uc_windcurtailment.mod")
model.set_data(df_nodes, "V")
model.set_data(df_edges, "E")
model.set["T"] = range(samples.shape[1])
model.set["W"] = df_nodes.index[df_nodes["energy_type"] == "wind"]
model.set["NW"] = df_nodes.index[df_nodes["energy_type"] != "wind"]
model.param["M"] = 1000
model.param["samples"] = samples
model.param["g"] = g
model.param["vmax"] = vmax
model.option["solver"] = SOLVER
return model
We sample from two different continuous Weibull distributions with different scale and shape parameters and then solve the problem.
seed = 0
rng = np.random.default_rng(seed)
scale64 = 15
shape64 = 2.6
scale65 = 18
shape65 = 3
nsamples = 100
samples = [
{64: scale64 * rng.weibull(shape64), 65: scale65 * rng.weibull(shape65)}
for i in range(nsamples)
]
g = [{k: g_func[k](s[k]) for k in s} for s in samples]
df_samples = pd.DataFrame(samples).T
df_g = pd.DataFrame(g).T
# Maximum wind speeds for each wind generator
vmax = {64: 20.0, 65: 22.0}
model = UC_windcurtailment(network, df_samples, df_g, vmax)
model.solve(verbose=False)
assert model.solve_result == "solved", model.solve_result
print(f"Objective value: {model.obj['objective'].value():.2f}")
y = model.var["y"].to_pandas()
y.index.names = ["W", "T"]
y = y.rename(columns={y.columns[0]: "y"})
W = [64, 65]
for w in W:
q = f"W == {w}"
v = y.query(q)["y"].sum()
print(f"Number of scenarios wind tubine {w} is active: {v:2.0f} out of {nsamples}")
Objective value: 29662.84
Number of scenarios wind tubine 64 is active: 18 out of 100
Number of scenarios wind tubine 65 is active: 16 out of 100
Assessing the quality of the solution#
How can we assess the quality of the solution? For example, we could investigate how it performs compared to some baseline solution: we could have assumed ‘average’ values for the wind speed and solve the problem like a single-stage problem where all the data is known. That would give us some initial here-and-now commitment decisions, for which we could check in how many cases is it not even possible to schedule the production \(p_i\) to meet the demand.
To do so, we need a variant of our model building function in which we can fix the initial decisions \(x_i\) and seek the best possible decisions for the other variables given an observed wind speed, for each of the \(T\) scenarios, and see how often is the problem infeasible. The following is a modified version of our function.
def UC_windcurtailment_fixed_x(network, samples, g, vmax, fixed_x=None):
model = UC_windcurtailment(network, samples, g, vmax)
df_nodes = network["nodes"]
G = df_nodes.query('is_generator and energy_type != "wind"').index
if fixed_x is not None:
for i in G:
model.var["x"][i].fix(fixed_x[i])
return model
Next, we construct our average sample, solve for it, and then optimize for the second stage decisions for each of the simulated scenarios separately.
T = len(samples)
mean_sample = [
{i: np.array([samples[t][i] for t in range(T)]).mean() for i in samples[0].keys()}
]
g = [{k: g_func[k](s[k]) for k in s} for s in mean_sample]
df_samples = pd.DataFrame(mean_sample).T
df_g = pd.DataFrame(g).T
m_nominal = UC_windcurtailment_fixed_x(network, df_samples, df_g, vmax)
m_nominal.solve(verbose=False)
assert m_nominal.solve_result == "solved", m_nominal.solve_result
print(f"Nominal objective = {m_nominal.obj['objective'].value():0.2f}")
fixed_x = m_nominal.var["x"].to_dict()
Nominal objective = 15101.25
Now, for each of our scenarios we will solve the problem by fixing the initial decisions to be the one for the ‘average’ scenario and see in how many of them we cannot obtain a feasible second-stage decision, which we extract using the try-except mechanism of Python catching an error in case we are trying to call a solution that does not exist.
# Variable to count the number of infeasible second stage problems
n_infeasible = 0
for t in range(T):
sample = [samples[t]]
g = [{k: g_func[k](s[k]) for k in s} for s in sample]
df_samples = pd.DataFrame(sample).T
df_g = pd.DataFrame(g).T
m_single = UC_windcurtailment_fixed_x(network, df_samples, df_g, vmax, fixed_x)
m_single.solve(verbose=False)
n_infeasible += 1 if m_single.solve_result == "infeasible" else 0
print(f"The second stage problem is infeasible in {n_infeasible} out of {T} instances")
The second stage problem is infeasible in 65 out of 100 instances
As it turns out, the ‘nominal’ commitment solution would lead to infeasibility, thus a blackout, in 65% of the cases. Since a blackout is the very last thing a network operator would like to happen, this clearly demonstrates the value of the stochastic solution. It is important to note that a very robust solution that avoids blackouts could be explained by simply assuming very poor performance of the wind turbines. Such a solution, however, could be unnecessarily conservative and expensive, and it is therefore better to prepare for a set of realistic scenarios.