Training Support Vector Machines with Conic Optimization#
In this notebook we come back to the concept of training support vector machines as we did in the first support vector machine notebook
The difference is that we shall now be solving the dual problems related to training the SVM’s using the conic quadratic optimization by explicitly calling the Mosek solver, which should yield more stable numerical results than general convex optimization.
The first part of this notebook shall therefore consist of data imports and other things that need no further explanation. Please move directly to the cell entitled “Conic optimization model” if you already have the data loaded from there.
Point of attention: An important difference with the first notebook will be the fact that we will eliminate the ‘intercept’ \(b\) of the SVM to keep our equations simple.
# install dependencies and select solver
%pip install -q amplpy numpy pandas scikit-learn matplotlib
SOLVER_CONIC = "mosek" # ipopt, mosek, gurobi, knitro
from amplpy import AMPL, ampl_notebook
ampl = ampl_notebook(
modules=["coin", "mosek"], # modules to install
license_uuid="default", # license to use
) # instantiate AMPL object and register notebook magics
The Data Set#
The following data set contains data from a collection of known genuine and known counterfeit banknote specimens. The data includes four continuous statistical measures obtained from the wavelet transform of banknote images named “variance”, “skewness”, “curtosis”, and “entropy”, and a binary variable named “class” which is 0 if genuine and 1 if counterfeit.
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
Read data#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# read data set
df = pd.read_csv(
"https://raw.githubusercontent.com/ampl/mo-book.ampl.com/refs/heads/dev/datasets/data_banknote_authentication.txt",
header=None,
)
df.columns = ["variance", "skewness", "curtosis", "entropy", "class"]
df.name = "Banknotes"
Select features and training sets#
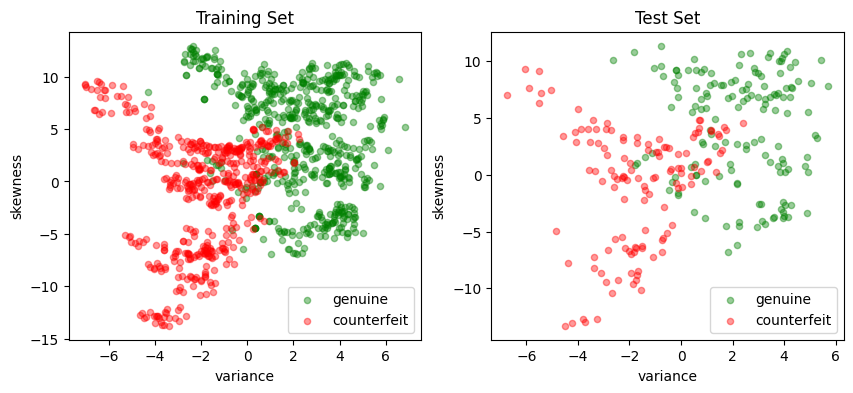
Following customary practices, we divide the data set into a training set used to trail the classifier, and a testing set that will be used to evaluate the performance of the classifier. In addition, we select two dimensional subset of the features to enable plotting of the results for exposition. Since our definition of a positive outcome corresponds to detecting a genuine banknote, we rescale the “class” feature to have values of 1 for genuine banknotes and -1 for counterfeit banknotes.
# create training and validation test sets
df_train, df_test = train_test_split(df, test_size=0.2)
# select training features
features = ["variance", "skewness"]
# separate into features and outputs
X_train = df_train[features]
y_train = 1 - 2 * df_train["class"]
# separate into features and outputs
X_test = df_test[features]
y_test = 1 - 2 * df_test["class"]
The following cell presents a simple function to create a scatter plot for a labeled 2D set of features. The function assigns default labels and colors, and passes along other keyword arguments.
def scatter_labeled_data(X, y, labels=["+1", "-1"], colors=["g", "r"], **kwargs):
"""
Creates a scatter plot for labeled data with default labels and colors.
Parameters:
X : DataFrame
Feature matrix as a DataFrame.
y : Series
Target vector as a Series.
labels : list, optional
Labels for the positive and negative classes. Default is ["+1", "-1"].
colors : list, optional
Colors for the positive and negative classes. Default is ["g", "r"].
**kwargs : dict
Additional keyword arguments for the scatter plot.
Returns:
None
"""
# Prepend keyword arguments for all scatter plots
kw = {"x": 0, "y": 1, "kind": "scatter", "alpha": 0.4}
kw.update(kwargs)
# Ignore warnings from matplotlib scatter plot
import warnings
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
kw["ax"] = X[y > 0].plot(**kw, c=colors[0], label=labels[0])
X[y < 0].plot(**kw, c=colors[1], label=labels[1])
# plot training and test sets in two axes
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
scatter_labeled_data(
X_train,
y_train,
labels=["genuine", "counterfeit"],
ax=ax[0],
title="Training Set",
)
scatter_labeled_data(
X_test,
y_test,
labels=["genuine", "counterfeit"],
ax=ax[1],
title="Test Set",
)
def scatter_comparison(X, y, y_pred):
"""
Creates scatter plots comparing actual and predicted outcomes for both training and test sets.
Parameters:
X : DataFrame
Feature matrix as a DataFrame.
y : Series
Actual target vector as a Series.
y_pred : Series
Predicted target vector as a Series.
Returns:
None
"""
xmin, ymin = X.min()
xmax, ymax = X.max()
xlim = [xmin - 0.05 * (xmax - xmin), xmax + 0.05 * (xmax - xmin)]
ylim = [ymin - 0.05 * (ymax - ymin), ymax + 0.05 * (ymax - ymin)]
# Plot training and test sets
labels = ["genuine", "counterfeit"]
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
scatter_labeled_data(
X, y, labels, ["g", "r"], ax=ax[0], xlim=xlim, ylim=ylim, title="Actual"
)
scatter_labeled_data(
X,
y_pred,
labels,
["c", "m"],
ax=ax[1],
xlim=xlim,
ylim=ylim,
title="Prediction",
)
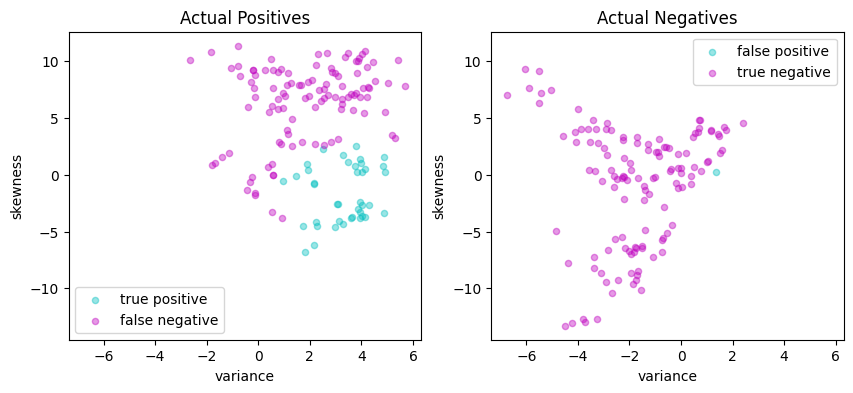
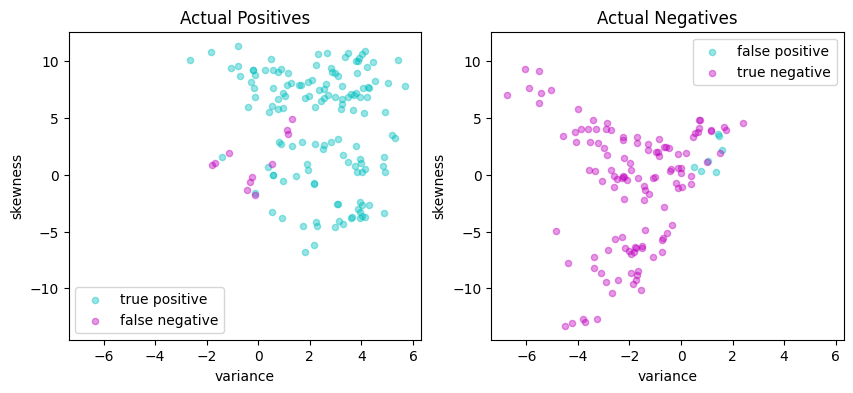
# Plot actual positives and actual negatives
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
scatter_labeled_data(
X[y > 0],
y_pred[y > 0],
["true positive", "false negative"],
["c", "m"],
xlim=xlim,
ylim=ylim,
ax=ax[0],
title="Actual Positives",
)
scatter_labeled_data(
X[y < 0],
y_pred[y < 0],
["false positive", "true negative"],
["c", "m"],
xlim=xlim,
ylim=ylim,
ax=ax[1],
title="Actual Negatives",
)
Performance metrics#
The accuracy score alone is not always a reliable metric for evaluating the performance of binary classifiers. For instance, when one outcome is significantly more frequent than the other, a classifier that always predicts the more common outcome without regard to the feature vector can achieve a very high accuracy score while being completely wrong on the less common outcome.
Moreover, in many applications, the consequences of a false positive can differ from those of a false negative. For these reasons, we seek a more comprehensive set of metrics to compare binary classifiers.
Sensitivity of a classifier measures how many of the actually positive items in the dataset have been labelled as positive.
Precision, on the other hand, counts how many of the items marked as positive, are actually positive.
A detailed discussion on this topic recommends the Matthews correlation coefficient (MCC) as a reliable performance measure for binary classifiers.
The code below demonstrates an example of a function that evaluates the performance of a binary classifier and returns the Matthews correlation coefficient as its output.
def validate(y_true, y_pred, verbose=True):
"""
This function calculates and displays the sensitivity, precision, and Matthews correlation coefficient
(MCC) for a binary classifier based on its true labels (y_true) and predicted labels (y_pred).
Args:
y_true (array-like): A list or array containing the true labels of the samples.
y_pred (array-like): A list or array containing the predicted labels of the samples.
verbose (bool, optional): If True, the function prints and displays the calculated metrics and
confusion matrix. Defaults to True.
Returns:
float: The calculated Matthews correlation coefficient (MCC).
"""
# Calculate the elements of the confusion matrix
true_positives = sum((y_true > 0) & (y_pred > 0))
false_negatives = sum((y_true > 0) & (y_pred < 0))
false_positives = sum((y_true < 0) & (y_pred > 0))
true_negatives = sum((y_true < 0) & (y_pred < 0))
total = true_positives + true_negatives + false_positives + false_negatives
# Calculate the Matthews correlation coefficient (MCC)
mcc_numerator = (true_positives * true_negatives) - (
false_positives * false_negatives
)
mcc_denominator = np.sqrt(
(true_positives + false_positives)
* (true_positives + false_negatives)
* (true_negatives + false_positives)
* (true_negatives + false_negatives)
)
mcc = mcc_numerator / mcc_denominator
if verbose:
print(f"Matthews correlation coefficient (MCC) = {mcc:0.3f}")
# report sensitivity and precision, and accuracy
sensitivity = true_positives / (true_positives + false_negatives)
precision = true_positives / (true_positives + false_positives)
accuracy = (true_positives + true_negatives) / total
print(f"Sensitivity = {100 * sensitivity: 0.1f}%")
print(f"Precision = {100 * precision: 0.1f}%")
print(f"Accuracy = {100 * accuracy: 0.1f}%")
# Display the binary confusion matrix
confusion_matrix = pd.DataFrame(
[
[true_positives, false_negatives],
[false_positives, true_negatives],
],
index=["Actual Positive", "Actual Negative"],
columns=["Predicted Positive", "Predicted Negative"],
)
display(confusion_matrix)
return mcc
def test(svm, X_test, y_test):
y_pred = svm(X_test)
print(svm, "\n")
validate(y_test, y_pred)
scatter_comparison(X_test, y_test, y_pred)
The following cell presents a simple Python implementation of a linear SVM. An instance of LinearSVM is defined with a coefficient vector and a scalar. In this implementation, all data and parameters are provided as Pandas Series or DataFrame objects, and the Pandas .dot() function is used to compute the dot product.
import pandas as pd
import numpy as np
# Linear Support Vector Machine (SVM) class
class LinearSVM:
# Initialize the Linear SVM with weights and bias
def __init__(self, w, b):
"""
Args:
w (Pandas Series or dictionary): Weights of the SVM
b (float): Bias of the SVM
"""
self.w = pd.Series(w)
self.b = float(b)
# Call method to compute the decision function
def __call__(self, X):
"""
Args:
X (pandas.DataFrame): Input data
Returns:
numpy.array: Array of decision function values
"""
return np.sign(X.dot(self.w) + self.b)
# Representation method for the Linear SVM class
def __repr__(self):
"""
Returns:
str: String representation of the Linear SVM
"""
return f"LinearSvm(w = {self.w.to_dict()}, b = {self.b})"
Conic optimization model#
Primal formulation#
As already explained in the first support vector machine notebook, the standard formulation of a linear support vector machine uses training sets with \(p\)-element feature vectors \(x_i\in\mathbb{R}^p\) along with classification labels for those vectors, \(y_i = \pm 1\). A classifier is defined by two parameters: a weight vector \(w\in\mathbb{R}^p\) and a bias term \(b\in\mathbb{R}\)
We train the classifier by developing and solving an optimization model for the values of \(w\) and \(b\). The presence of parameter \(b\), however, unnecessarily complicates the presentation and derivation of the model. To simplify, we introduce an augmented feature vector \(\bar{x} = (1, x) \in \mathbb{R}^{p+1}\) and an augmented weight vector \(\bar{w} = (b, w) \in \mathbb{R}^{p+1}\) so the classifier can be presented as
Given a value of \(\bar{w}\), there is a family of hyperplanes in \(\mathbb{R}^{p+1}\) orthogonal to \(\bar{w}\). A separating hyperplane, if one exists, separates all data points with \(y_i = 1\) from those with \(y_i = -1\). The distance between \(\bar{x}_i\) and the separating hyperplane is the length of the projection \(\bar{x}_i\) onto \(\bar{w}\), which is
If a separating hyperplane exists, then we can choose the norm of \(\bar{w}\) so that a hard-margin classifier exists for the training set \((\bar{x}_i, y_i)\) where
Otherwise, if a separating hyperplane does not exist, we introduce non-negative slack variables \(z_i\) to relax the constraints and settle for a soft-margin classifier
Given \(\bar{w}\), training data for which \(z_i > 1\) are misclassified. The training objective is to minimize the number and distance to misclassified data points. This leads to the optimization problem
where \(\frac{1}{2} \|\bar{w}\|_2^2\) is included to regularize the solution for \(\bar{w}\). Choosing larger values of \(c\) will reduce the number and size of misclassifications. The trade-off will be larger weights \(\bar{w}\) and the accompanying risk of over over-fitting the training data.
To simplify the presentation of the model, we introduce an \(n \times (p+1)\) matrix \(F\) constructed from the training data
Next we introduce a rotated quadratic cone defined as
and parameter \(r\) where
With these additional components, the primal problem is now a conic optimization problem ready for implementation with AMPL and Mosek conic solver.
Like for the previous case, the Python implementation is a “factory” function that returns a linear SVM.
%%writefile svm_conic_primal.mod
param p;
param n;
param c;
param F{1..n, 1..p+1};
# decision variables
var r;
var w{1..p+1};
var z{1..n} >= 0;
# objective
minimize primal:
r + (c / n) * sum {i in 1..n} z[i];
# constraints
s.t. qr:
r >= sum {j in 1..p+1} w[j]^2;
s.t. d{i in 1..n}:
z[i] + sum {j in 1..p+1} F[i, j] * w[j] >= 1;
Overwriting svm_conic_primal.mod
def conicSvmFactory(X, y, c=1):
# create data matrix F
n, p = X.shape
F = np.array(
[y.iloc[i] * np.append(1, X.iloc[i, :].to_numpy()) for i in range(n)]
) # Appending 1's to features
# Create AMPL instance and load the model
ampl = AMPL()
ampl.read("svm_conic_primal.mod")
# load the data
ampl.param["p"] = p
ampl.param["n"] = n
ampl.param["c"] = c
ampl.param["F"] = {(i + 1, j + 1): F[i, j] for i in range(n) for j in range(p + 1)}
# solve
ampl.solve(solver=SOLVER_CONIC)
assert ampl.solve_result == "solved", ampl.solve_result
# return svm
wd = ampl.get_variable("w")
w = wd.to_dict()
b = w[1]
w = pd.Series({k: w[j + 2] for j, k in enumerate(X.columns)})
return LinearSVM(w, b)
svm_v2 = conicSvmFactory(X_train, y_train, c=10)
print(svm_v2.w)
print(svm_v2.b)
MOSEK 10.0.43: MOSEK 10.0.43: optimal; objective 3.152925656
0 simplex iterations
17 barrier iterations
variance 0.512465
skewness 0.154969
dtype: float64
-0.1264366951975979
The following cell with reveal the performance of this standard SVM.
y_pred = svm_v2(X_test)
validate(y_test, y_pred)
scatter_comparison(X_test, y_test, y_pred)
Matthews correlation coefficient (MCC) = 0.745
Sensitivity = 91.9%
Precision = 85.5%
Accuracy = 87.3%
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 136 | 12 |
| Actual Negative | 23 | 104 |
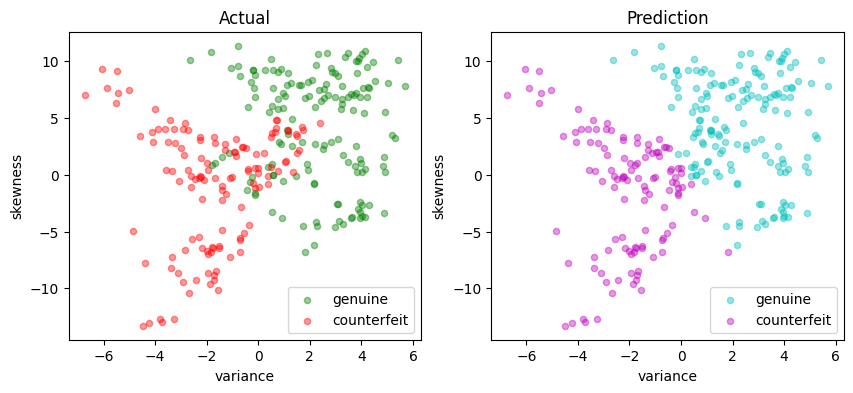
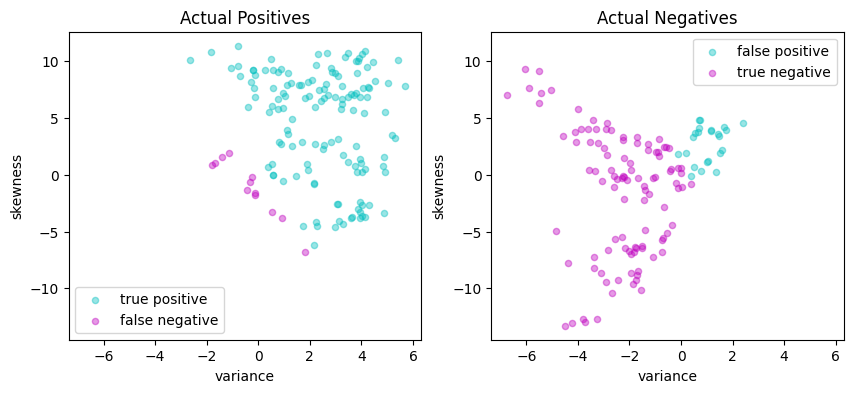
Dual formulation#
As we already know, the dual of our problem shall be given by $\( \begin{align*} \min \quad & \frac{1}{2} \sum_{i=1}^n\sum_{j=1}^n \alpha_i \alpha_j y_i y_j ( \bar{x}_i^\top \bar{x}_j ) - \sum_{i=1}^n \alpha_i \\ \text{s.t.}\quad & \alpha_i \in \left[0, \frac{c}{n}\right] & i = 1, \dots, n. \\ \end{align*} \)$
The symmetric \(n \times n\) Gram matrix is defined as
where each entry is dot product of two vectors \((y_i\bar{x}_i), (y_j\bar{x}_j) \in \mathbb{R}^{p+1}\).
Compared to the primal, the dual formulation appears to have reduced the number of decision variables from \(n + p + 1\) to \(n\). But this has come with the penalty of introducing a dense matrix with \(n^2\) coefficients and potential processing time of order \(n^3\). For large training sets where \(n\sim 10^4-10^6\) or even larger, this becomes a prohibitively expensive calculation. In addition, the Gram matrix will be rank deficient for cases \(p+1 < n\).
Reformulating the dual problem as a conic optimization problem eliminates the need to compute and store the full Gram matrix \(G\). The reformulation begins by use the \(n \times (p+1)\) matrix \(F\) previously introduced in the primal problem:
Then \(G = FF^\top\) and the optimization problem becomes
We introduce an additional decision variable \(r \geq 0\) to specify rotated quadratic cones. Let \(z = F^\top\alpha\), then
The result is a conic optimization problem for the dual coefficients \(\alpha\) and auxiliary variables \(r\) and \(z\).
The solution to dual formulation provides an alternative expression for the resulting support vector machine. Let \({SV}\) represent the set of support vectors, which can be implemented as the set of indices for which \(\alpha_i > 0\). Then SVM can be expressed as either
or, more directly, as
The first formulation of a linear SVM is a computationally efficient, and used in the following AMPLPY implementation. The second formulation, however, provides additional insight into how an SVM works, and is the basis for important generalizations of SVM including the kernelized SVM discussed below. Remember, we no longer need to derive the value of the primal variable \(b\) because we eliminated its existence by stacking 1’s into the feature vector.
The following code implements the above SVM dual formulation.
AMPL implementation#
%%writefile svm_conic_dual.mod
param p;
param n;
param c;
param F{1..n, 1..p+1};
# decision variables
var r;
var a{1..n} >=0 <=c/n;
var z{1..p+1};
# objective
minimize dual:
r - sum {i in 1..n} a[i];
# constraints
s.t. d{j in 1..p+1}:
z[j] == sum {i in 1..n} F[i, j] * a[i];
s.t. q:
r >= sum {j in 1..p+1} z[j]^2;
Overwriting svm_conic_dual.mod
def conicDualSVMFactory(X, y, c=1):
n, p = X.shape
F = np.array(
[y.iloc[i] * np.append(1, X.iloc[i, :].to_numpy()) for i in range(n)]
) # Appending 1's to features
# Create AMPL instance and load the model
ampl = AMPL()
ampl.read("svm_conic_dual.mod")
# load the data
ampl.param["p"] = p
ampl.param["n"] = n
ampl.param["c"] = c
ampl.param["F"] = {(i + 1, j + 1): F[i, j] for i in range(n) for j in range(p + 1)}
# solve
ampl.solve(solver=SOLVER_CONIC)
assert ampl.solve_result == "solved", ampl.solve_result
# return svm
ad = ampl.get_variable("a")
a = ad.to_dict()
# get the support
S = [i for i in range(n) if (a[i + 1] > 0)]
# create and return linear SVM
w_bar = sum(a[i + 1] * F[i, :] for i in S)
w = pd.Series({k: w_bar[j + 1] for j, k in enumerate(X.columns)})
b = w_bar[0]
y_support = pd.Series([1 if a[i + 1] > 0 else -1 for i in range(n)], index=X.index)
scatter_labeled_data(
X,
y_support,
colors=["b", "y"],
labels=["Support Vector", ""],
title="Support Vectors",
)
return LinearSVM(w, b)
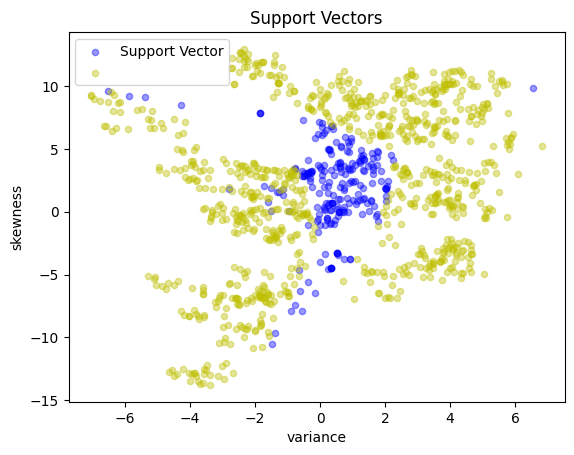
svm_v3 = conicDualSVMFactory(X_train, y_train, c=10)
print(svm_v3.w, svm_v3.b)
MOSEK 10.0.43: MOSEK 10.0.43: optimal; objective -2.879361347
0 simplex iterations
16 barrier iterations
variance 0.306301
skewness 0.091532
dtype: float64 -0.13436884955210832
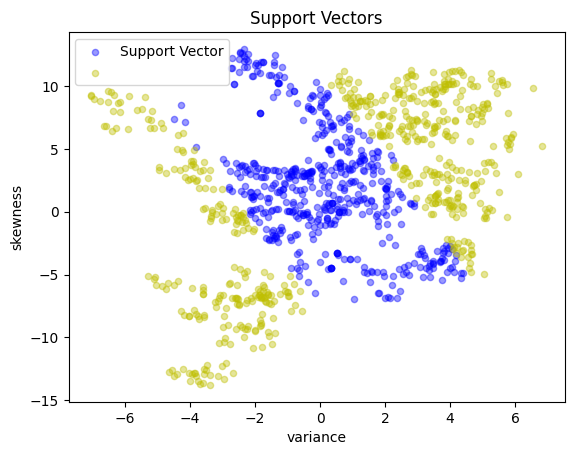
The following cell implements the above conic dual formulation and should obtain exactly the same accuracy results.
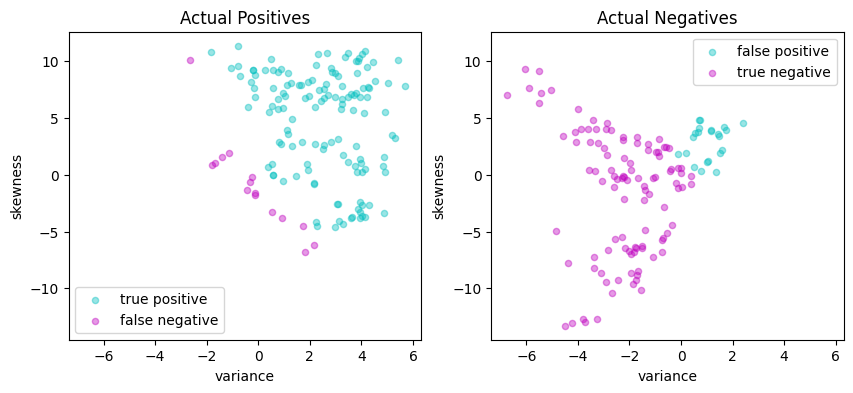
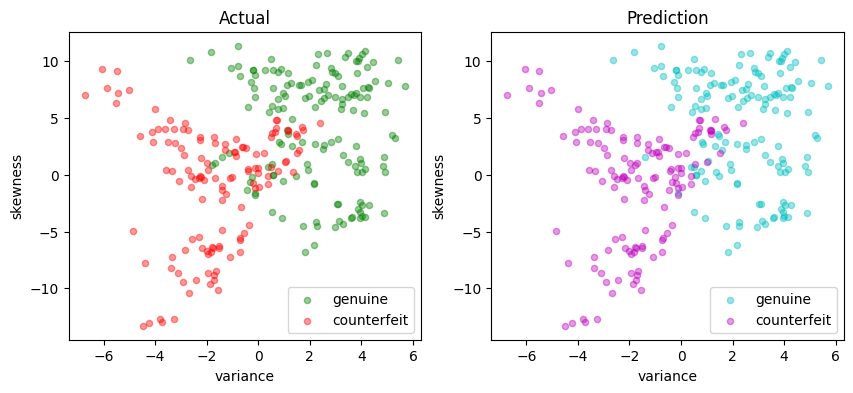
y_pred = svm_v3(X_test)
validate(y_test, y_pred)
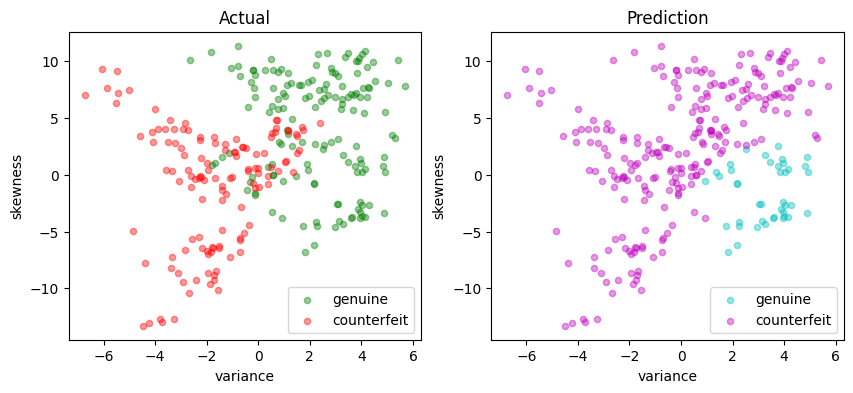
scatter_comparison(X_test, y_test, y_pred)
Matthews correlation coefficient (MCC) = 0.729
Sensitivity = 89.9%
Precision = 85.8%
Accuracy = 86.5%
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 133 | 15 |
| Actual Negative | 22 | 105 |
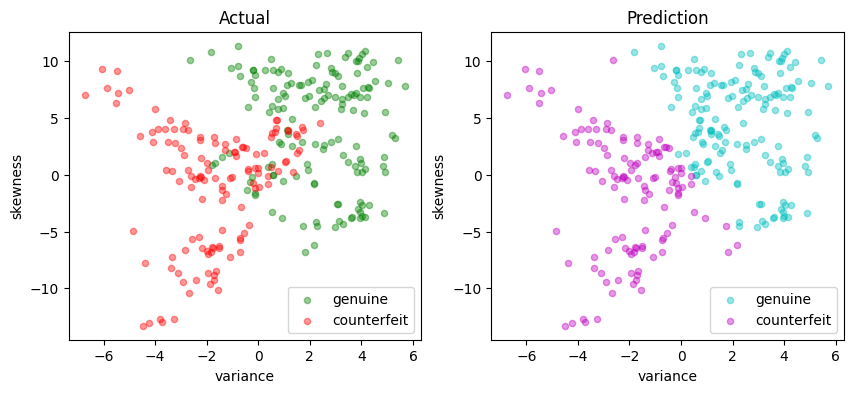
Kernelized SVM#
Nonlinear feature spaces#
A linear SVM assumes the existence of a linear hyperplane that separates labeled sets of data points. Frequently, however, this is not possible and some sort of nonlinear method where the feature vector is appended with nonlinear transformations
where \(\phi(\bar{x})\) is a function mapping \(x\) into a higher dimensional “feature space”. That is, \(\phi : \mathbb{R}^{p + 1} \rightarrow \mathbb{R}^d\) where \(d \geq p +1 \). The additional dimensions may include features such as powers of the terms in \(x\), or products of those terms, or other types of nonlinear transformations. In this way, the SVM has more ‘room to play’ in order to try to separate one point from another.
Corresponding to such a transformed vector, we have a binary classification tool given by
From now onwards, the derivation of the dual problem goes exactly the same way as in the linear SVM case (please refer to the first support vector machine notebook ), and we arrive at:
The kernel trick#
If you look at the optimization problem above and the corresponding classifier tool, this is an interesting situation where the separating hyperplane is embedded in a high dimensional space of nonlinear features determined by the mapping \(\phi(\bar{x})\), but all we need to train the classifier and to use the classifier are the inner products \(\phi(\bar{x}_i)^\top\phi(\bar{x}_j)\) and \(\phi(\bar{x}_i)^\top\phi(x)\), rather than the ‘raw’ \(\phi(\bar{x}_i)\) and \(\phi(\bar{x})\) values. If we had a function \(K(\bar{x}, \bar{z})\) that returned the value \(\phi(\bar{x})^\top\phi(\bar{z})\) then we would never need to actually compute \(\phi(\bar{x})\), \(\phi(\bar{z})\) or their inner product.
Mercer’s theorem turns the analysis on its head by specifying conditions for which a function \(K(\bar{x}, \bar{z})\) to be expressed as an inner product for some \(\phi(x)\). If \(K(\bar{x}, z)\) is symmetric (i.e, \(K(\bar{x}, \bar{z}) = K(\bar{z}, \bar{x})\), and if the Gram matrix constructed for any collection of points \(x_1, x_2, \ldots, x_n\)
is positive semi-definite, then there is some \(\phi(\bar{x})\) for which \(K(\bar{x}, \bar{z})\) is an inner product. We call such functions kernels. The practical consequence is that we can train and implement nonlinear classifiers using kernel and without ever needing to compute the higher dimensional features. This remarkable result is called the “kernel trick”.
Implementation#
To take advantage of the kernel trick, we assume an appropriate kernel \(K(\bar{x}, \bar{z})\) has been identified, then replace all instances of \(\phi(\bar{x_i})^\top \phi(\bar{x})\) with the kernel. The “kernelized” SVM is then given by solution to
where the resulting classifier is given by
We define the \(n\times n\) positive symmetric semi-definite Gram matrix
We factor \(G = FF^\top\) where \(F\) has dimensions \(n \times q\) and where \(q\) is the rank of \(G\). This factorization is not unique. As demonstrated in the Python code below, one suitable factorization is the spectral factorization \(G = U\Lambda U^T\) where \(\Lambda\) is a \(q\times q\) diagonal matrix of non-zero eigenvalues, and \(U\) is an \(n\times q\) normal matrix such that \(U^\top U = I_q\). Then
Once this factorization is complete, the optimization problem for the kernalized SVM is the same as for the linear SVM in the dual formulation
The result is a conic program for the dual coefficients \(\alpha\) and auxiliary variables \(r\) and \(z\).
Summarizing, the essential difference between training the linear and kernelized SVM is the need to compute and factor the Gram matrix. The result will be a set of non-zero coefficients \(\alpha_i > 0\) the define a set of support vectors \(\mathcal{SV}\). The classifier is then given by
The following cell implements this model, leaving it to the user to specify the kernel function via a lambda-function argument.
def kernelSVMFactory(X, y, c, tol=1e-8, kernel=lambda x, z: (x @ z)):
n, p = X.shape
# convert to numpy arrays for speed
X_ = np.hstack([np.ones((n, 1)), X.to_numpy()])
y_ = y.to_numpy()
# kernel matrix
G = [
[y_[i] * y_[j] * kernel(X_[i, :], X_[j, :]) for j in range(n)] for i in range(n)
]
# spectral factors for a positive semi-definite matrix
eigvals, V = np.linalg.eigh(G)
idx = eigvals >= tol * max(eigvals)
F = V[:, idx] @ np.diag(np.sqrt(eigvals[idx]))
q = sum(idx)
# Create AMPL instance and load the model
ampl = AMPL()
ampl.read("svm_conic_dual.mod")
# load the data
ampl.param["p"] = q - 1.0
ampl.param["n"] = n
ampl.param["c"] = c
ampl.param["F"] = {(i + 1, j + 1): F[i, j] for i in range(n) for j in range(q)}
# solve
ampl.solve(solver=SOLVER_CONIC)
assert ampl.solve_result == "solved", ampl.solve_result
# return svm
ad = ampl.get_variable("a")
a = ad.to_dict()
y_support = pd.Series(
[1 if a[i + 1] > 1e-3 * c / n else -1 for i in range(n)], index=X.index
)
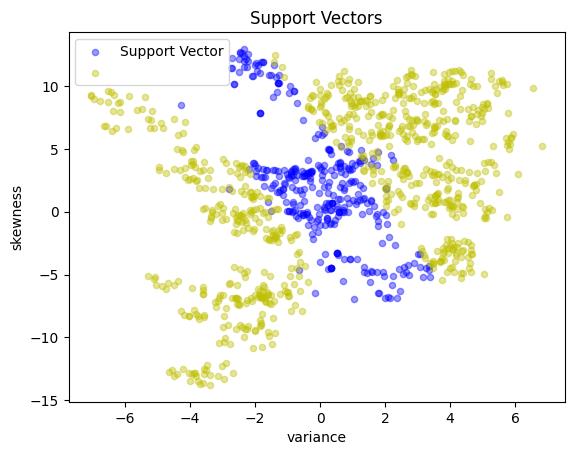
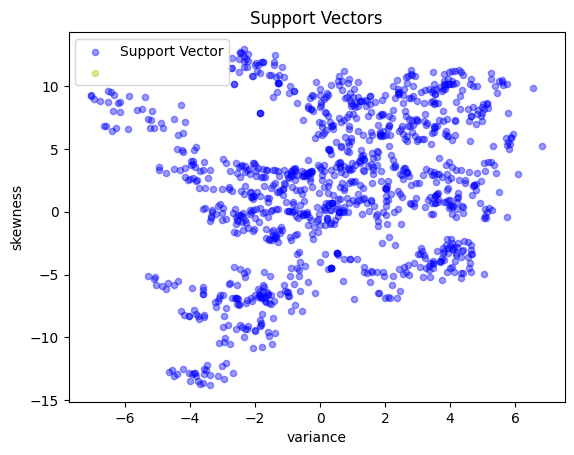
scatter_labeled_data(
X,
y_support,
colors=["b", "y"],
labels=["Support Vector", ""],
title="Support Vectors",
)
# get indices of the support vectors
SV = [i for i in range(n) if (a[i + 1] > 1e-3)]
def kernelSVM(Z):
nz, pz = Z.shape
Z_ = np.hstack([np.ones((nz, 1)), Z.to_numpy()])
y_pred = pd.Series(
[
np.sign(sum(a[i + 1] * y_[i] * kernel(X_[i, :], Z_[j, :]) for i in SV))
for j in range(nz)
],
index=Z.index,
)
return y_pred
return kernelSVM
Linear kernel#
A linear kernel reduces the kernelized SVM to the previous case.
This is useful for verifying the calculation because we can check if we obtain indeed the same results.
svm = kernelSVMFactory(X_train, y_train, c=10, kernel=lambda x, z: x @ z)
y_pred = svm(X_test)
validate(y_test, y_pred)
scatter_comparison(X_test, y_test, y_pred)
MOSEK 10.0.43: MOSEK 10.0.43: optimal; objective -2.879363522
0 simplex iterations
16 barrier iterations
Matthews correlation coefficient (MCC) = 0.729
Sensitivity = 89.9%
Precision = 85.8%
Accuracy = 86.5%
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 133 | 15 |
| Actual Negative | 22 | 105 |
Radial basis function kernel#
A radial basis function kernal is given by
The radial basis function is commonly used as the default kernel in SVM applications and as we shall see, it can give a significant boost to the predictive performance of our tool.
rbf = lambda x, z: np.exp(-10 * np.linalg.norm(x - z) ** 2)
svm = kernelSVMFactory(X_train, y_train, c=10, kernel=rbf)
y_pred = svm(X_test)
validate(y_test, y_pred)
scatter_comparison(X_test, y_test, y_pred)
MOSEK 10.0.43: MOSEK warning 705: #946 (nearly) zero elements are specified in sparse row ''(0) of matrix 'A'.
MOSEK warning 705: #1013 (nearly) zero elements are specified in sparse row ''(1) of matrix 'A'.
MOSEK warning 705: #701 (nearly) zero elements are specified in sparse row ''(2) of matrix 'A'.
MOSEK warning 705: #740 (nearly) zero elements are specified in sparse row ''(3) of matrix 'A'.
MOSEK warning 705: #985 (nearly) zero elements are specified in sparse row ''(4) of matrix 'A'.
MOSEK warning 705: #721 (nearly) zero elements are specified in sparse row ''(5) of matrix 'A'.
MOSEK warning 705: #650 (nearly) zero elements are specified in sparse row ''(6) of matrix 'A'.
MOSEK warning 705: #704 (nearly) zero elements are specified in sparse row ''(7) of matrix 'A'.
MOSEK warning 705: #812 (nearly) zero elements are specified in sparse row ''(8) of matrix 'A'.
MOSEK warning 705: #708 (nearly) zero elements are specified in sparse row ''(9) of matrix 'A'.
MOSEK 10.0.43: optimal; objective -9.680650134
0 simplex iterations
5 barrier iterations
Matthews correlation coefficient (MCC) = 0.869
Sensitivity = 92.6%
Precision = 95.1%
Accuracy = 93.5%
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 137 | 11 |
| Actual Negative | 7 | 120 |
Polynomial kernel#
Another important kernel function type is the polynomial kernel (which corresponds to including in the feature vector the powers of all featurs up to a certain degree \(d\)). $\(K(x, z) = (1 + x^\top z)^d\)\( Again, the higher the value of \)d\(, the more predictive power we can expect from the corresponding SVM, therefore, we encourage you to try this formulation varying \)d$.
poly = lambda x, z: (1 + (x @ z)) ** 2
svm = kernelSVMFactory(X_train, y_train, c=10, kernel=poly)
y_pred = svm(X_test)
validate(y_test, y_pred)
scatter_comparison(X_test, y_test, y_pred)
MOSEK 10.0.43: MOSEK 10.0.43: optimal; objective -1.866542517
0 simplex iterations
21 barrier iterations
Matthews correlation coefficient (MCC) = 0.367
Sensitivity = 27.0%
Precision = 97.6%
Accuracy = 60.4%
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | 40 | 108 |
| Actual Negative | 1 | 126 |